概述
本篇中你将了解几种常见的激活函数,并看到在浅层神经网络中向后传播及梯度下降是如何进行的。

5.0 上篇回顾
在上一篇中,你见到了一个单输出的浅层(双层)神经网络是如何进行向前传播的,就同 Logistic 回归网络一样,不过多重复了几次单层网络的向前传播过程而已。
对于隐藏层而言,所有的隐藏单元与输入层都构成了简单的单层网络结构,所有的隐藏单元均进行一次向前传播(图1-0左),所有隐藏单元完成向前传播后,隐藏层的输出数据就作为输出层的输入数据,继续向前推进,完成输出层的向前传播(图1-0右)。
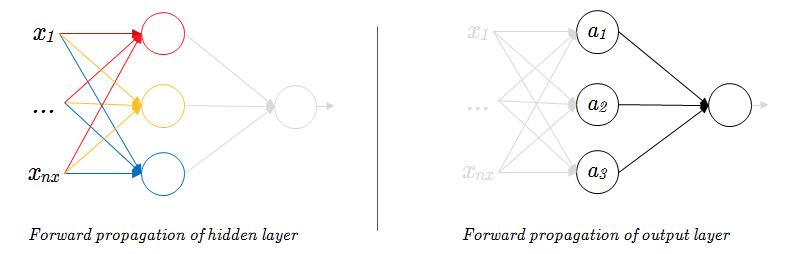
如果你了解了 Logistic 回归的向前传播过程,那么浅层神经网络当中的向前传播是很好理解的。
还记得在上篇的末尾留下了一个问题,即激活函数的选择。在之前我们一直使用的是 sigmoid 函数:
sigmoid 函数帮助我们将 Logistic 线性回归值进行归一化处理,得到一个位于区间 $[0,1]$ 的概率输出。但在浅层神经网络以至于在深层神经网络当中,尽管 sigmoid 函数可以继续用于输出层,但往往不会作为隐藏层的激活函数,而是使用其它的一些函数,如 tanh、ReLU、Leaky ReLU 等,这是为什么?下面就来了解一下这些新奇的函数,以及为什么要使用这些函数而不是 sigmoid 函数吧。
5.1 激活函数的选择
tanh
tanh 函数是双曲函数中的一个,更准确的说是双曲正切函数。首先来看一看 tanh 函数,它的函数表达式是这样的:
如果你对数学敏感的话,或许可以发现它与 sigmoid 函数的相似之处。如果观察图像的话,可以更加直观地看到,tanh 函数的形态与 sigmoid 函数是非常相似的,事实上 tanh 就是 sigmoid 函数的一个伸缩平移版本,两者是线性相关的。
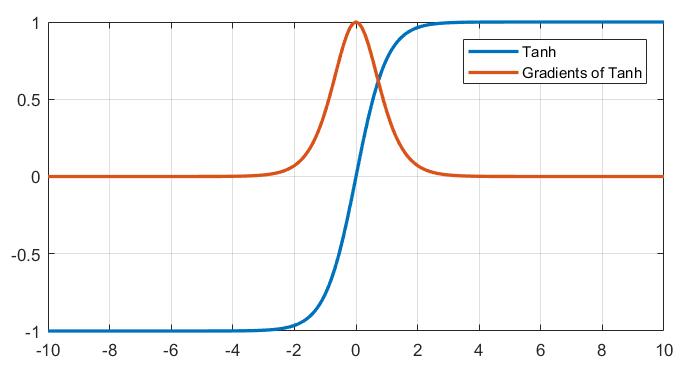
你可能会疑惑,既然 tanh 函数与 sigmoid 函数形态如此相似,为什么不直接使用 sigmoid 函数而是要换用一个看上去更复杂的 tanh 函数?答案很简单,tanh 函数可以很好的规避 sigmoid 函数导致的 zigzag 现象。如果你观察 tanh 函数的值域的话,你会发现它处于区间 $[-1,1]$,并且其中心点在坐标原点处,这意味着 tanh 是 0 均值的,这对神经网络的训练很有帮助。
零均值能避免 zigzag?能提高网络的训练效率?WHY?
如果你对原理不感兴趣,只需要知道上面一行黑体字是结论就行了。不过如果感兴趣,我们来从根本上看一看 sigmoid 函数为什么效率上不如零均值的 tanh 函数吧。
最大的问题在于 sigmoid 函数的输出全部是非负的,这直接导致了下一层网络在反向传播的过程中同层同单元参数 $w$ 的更新梯度总是同向的。想一想这是为什么?又会导致什么后果?
公式(3) 给出了第 $l$ 层第 $i$ 个神经元中所有 $j$ 个参数 $w$ 反向传播的梯度通式:
在第 $l-1$ 层采用 sigmoid 函数作为激活函数的情况下,你将发现第 $l$ 层同单元的梯度系数 $a^{[l-1]}_i$ 将是恒正的,这就意味着所有 $\frac{\partial J}{\partial w^{l}_i}$ 的正负均取决于同一个值 $\frac{\partial J}{\partial z^{[l]}_i}$ 的正负。也就是说,同单元的 $w$ 无法通过各自合理的情况去独立地增大或减小,要增大只能一起增大,要减小只能一起减小,很大程度上限制了参数优化的自由度,影响了神经网络的训练效率。
而反观零均值的 tanh 函数输出有正有负,就可以在一定程度上避免这一缺陷,这也是使用 tanh 激活函数代替 sigmoid 函数能够得到更好训练效果的原因。
ReLU
ReLU(Rectified Linear Unit),又叫线性整流函数、线性修正单元,是进来神经网络的隐藏层中被普遍选用的激活函数,其表达式如公式(4)所示:
\begin{equation}
ReLU(z)=\left{
\begin{array}{rcl}
z & & {z>0}\
0 & & {z<0}
\end{array} \right.
\end{equation}
当然也有更简洁的表示方式:
\begin{equation}
ReLU(z)=max(0,z)
\end{equation}
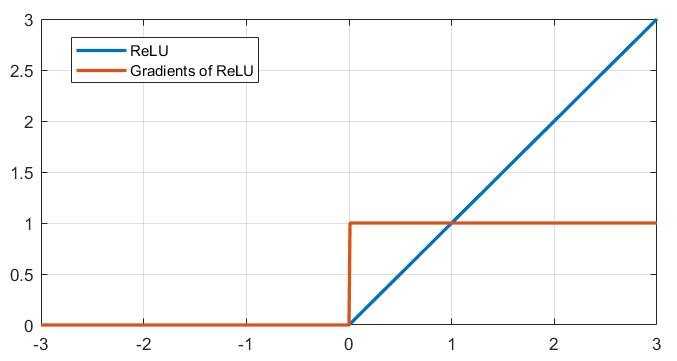
上图1-2严格上来说在横轴的零刻度处应当标注空心点,这也意味着 ReLU 函数在原点处是不可微的,尽管在实际情况下出现完全为零的前驱输入是概率很小的,但为了避免这种未定义在反向传播中造成错误,在实际的使用过程中通常手动为其原点处添加函数值定义及其导数定义。
\begin{equation}
ReLU(z)=\left{
\begin{array}{rcl}
z & & {z>0}\
0 & & {z \leq 0}
\end{array} \right.
\end{equation}
如果你了解 tanh 与 sigmoid 作为隐藏层激活函数的通病的话,那么采用 ReLU 作为激活函数的优点就显而易见了。
虽然 tanh 缓解了 sigmoid 输出恒正造成的锯齿状梯度下降,但其同样具有“饱和区”,即当绝对值较大的数作为输入时,梯度会接近于零,这一点从二者的函数图像上显而易见,当输入 $x$ 趋近与无穷大/小时,图像基本上平了,这会导致梯度更新几乎失活。而 ReLU 函数则不同,在 $x>0$ 的区域,ReLU 的导数具有一个恒定的值,可以保证梯度下降能够在大输入下依旧持续工作。
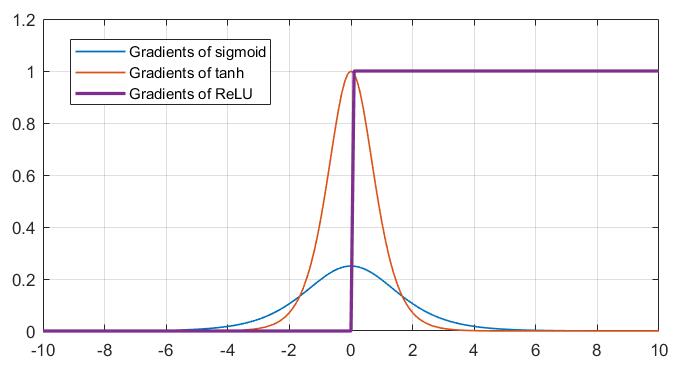
你可能会疑问:可是 ReLU 函数和 sigmoid 函数一样,也是非零均值的?
的确,使用 tanh 代替 sigmoid 就是为了提高其迭代效率,可是虽然 ReLU 也是非零均值函数,但是 ReLU 不需要求自然指数呀,因此其计算复杂度要远远小于 tanh,就算非零均值,小计算量也可以帮助 ReLU 的梯度快速收敛。总而言之,瑕不掩瑜。
不过,ReLU 函数有一个问题——在负数区硬饱和。当输入落在小于零的区间时,ReLU 函数将直接输出零,这种现象被称作Dead ReLU,但这一特性也被列入 ReLU 的优势:
仿生物学原理:相关大脑方面的研究表明生物神经元的信息编码通常是比较分散及稀疏的。通常情况下,大脑中在同一时间大概只有1%-4%的神经元处于活跃状态。使用线性修正以及正则化(regularization)可以对机器神经网络中神经元的活跃度(即输出为正值)进行调试;相比之下,逻辑函数在输入为0时达到 ,即已经是半饱和的稳定状态,不够符合实际生物学对模拟神经网络的期望。不过需要指出的是,一般情况下,在一个使用修正线性单元(即线性整流)的神经网络中大概有50%的神经元处于激活态。
——百度百科
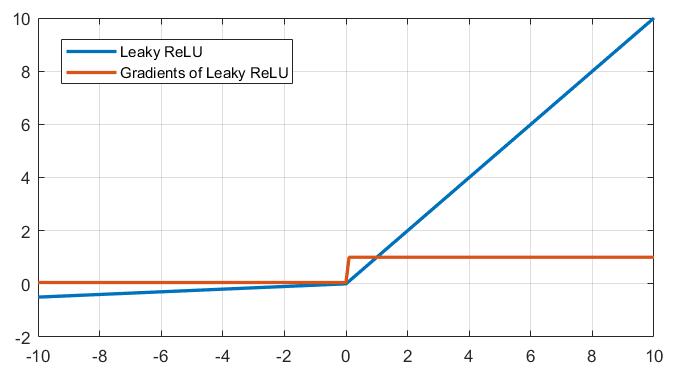
Leaky ReLU
如果你不希望看到 Dead ReLU 的情况,可以使用 Leaky ReLU 来代替 ReLU:
\begin{equation}
LeakyReLU(z)=\left{
\begin{array}{rcl}
z & & {z>0}\
\alpha z & & {z<0}
\end{array} \right.
\end{equation}
Leaky ReLU 与 ReLU 的区别仅仅在于当输入量小于零时,引入了一个极小的梯度 $\alpha$(图1-4中取值为0.05),使得神经元不至于被完全抑制,但是这种做法的优劣不好评定,在一些情况下,Leaky ReLU 可能表现更好,另一些情况下可能 ReLU 更胜一筹,谁知道呢。
5.2 浅层网络的向后传播
聊完了几种常见的激活函数,现在回过神来,看一看浅层神经网络的向后传播吧。还记得在 Logistic 回归当中,向后传播的 $dz$ 直接一步到位用 $a-y$ 来表示了,这是默认将 sigmoid 作为激活函数后用链式法则求导化简后的结果。但现在我们知道了,激活函数的选择是多种多样的,那么在浅层神经网络当中隐藏层激活函数不确定的情况下,就不能够用沿用之前的结果了。
同样也是为了方便后续的深层神经网络叙述,下面将统一使用符号 $g^{[l]}$ 代表第 $l$ 层使用的激活函数,$dg^{[l]}$ 表示第 $l$ 层激活函数关于成本函数的导数。
5.3 浅层网络的梯度下降
5.4 浅层神经网络小结
没有隐藏内容(・∀・(・∀・(・∀・*)
