- 所有题目来源为力扣
- 题解为原创,仅为个人当前阶段能想到/能接受的解法,不一定是优解
🟢简单 🟠中等 🔴困难 ⚪未完成 ⚫未更新
有回顾价值题集:
- 🟠 2021.08.25 (787. K 站中转内最便宜的航班)
- 🔴 2021.08.18 (552. 学生出勤记录 II)
- 🟠 2021.08.15 (576. 出界的路径数)
- 🟠 2021.08.09 (313. 超级丑数)
其它题解:我的 LeetCode 题解
🟢 2021.11.01 (237. 删除链表中的节点)
题目
请编写一个函数,用于 删除单链表中某个特定节点 。在设计函数时需要注意,你无法访问链表的头节点 head ,只能直接访问 要被删除的节点 。
题目数据保证需要删除的节点 不是末尾节点 。
示例 1:
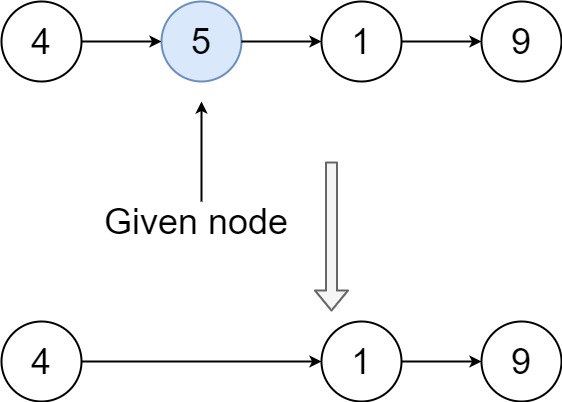
1 | 输入:head = [4,5,1,9], node = 5 |
示例 2:
1 | 输入:head = [0,1], node = 0 |
提示:
- 链表中节点的数目范围是
[2, 1000] -1000 <= Node.val <= 1000- 链表中每个节点的值都是唯一的
- 需要删除的节点
node是 链表中的一个有效节点 ,且 不是末尾节点
题解
额。这实在没什么可写的。因为要删除的必不是末尾节点,那么直接将当前要删除的节点“顶替”成下一个节点就成了。
完整代码:
1 | /** |
🟢 2021.10.31 (500. 键盘行)
题目
给你一个字符串数组 words ,只返回可以使用在 美式键盘 同一行的字母打印出来的单词。键盘如下图所示。
美式键盘 中:
- 第一行由字符
"qwertyuiop"组成。 - 第二行由字符
"asdfghjkl"组成。 - 第三行由字符
"zxcvbnm"组成。

示例 1:
1 | 输入:words = ["Hello","Alaska","Dad","Peace"] |
提示:
1 <= words.length <= 201 <= words[i].length <= 100words[i]由英文字母(小写和大写字母)组成
题解
本题显然逃不掉的就是遍历 words 中每一个单词的每一个字母在键盘各行的出现情况,也就是说搜索是高频操作, 据此不妨预打三张 HashMap,存储键盘对应三行存在的字母,然后在遍历 words 的过程中,对每一个 word 的验证就可以依次在三张 HashMap 中 $O(1)$ 地查验每一个字母是否在该行存在。如果所有字母都在某行存在,那么就不必搜索后面地行,可是直接加入答案集,验证下一个单词。若存在字母不在当前搜索行,则该单词必然不满足全在当前行的要求,直接验证是否全在下一行。
完整代码:
1 | class Solution { |
🟠 2021.10.30 (260. 只出现一次的数字 III)
题目
给定一个整数数组 nums,其中恰好有两个元素只出现一次,其余所有元素均出现两次。 找出只出现一次的那两个元素。你可以按 任意顺序 返回答案。
进阶:你的算法应该具有线性时间复杂度。你能否仅使用常数空间复杂度来实现?
示例 1:
1 | 输入:nums = [1,2,1,3,2,5] |
提示:
2 <= nums.length <= 3 * 10^4-2^31 <= nums[i] <= 2^31 - 1- 除两个只出现一次的整数外,
nums中的其他数字都出现两次
题解
首先不难直观地想到通过一次遍历统计 nums 中所有数字的出现次数,然后再选出出现次数为 1 的数字作为答案返回。
完整代码:
1 | class Solution { |

不过这样使用了 $O(n)$ 的空间复杂度,不满足本题的进阶要求,即在时间复杂度为 $O(n)$ 的前提下只使用 $O(1)$ 的空间复杂度。
通过利用 其余所有元素均出现两次 这一条件,结合 x^y^y = x,即用同一个数字异或两次后原数值不变的运算特性可知,若将 nums 中的所有元素全部与 0 异或的话,最终的结果将只是那两个出现一次的数字的异或结果,而其余出现两次的数字在两次异或中被抵消了。借助 2 个目标数字的异或结果,可以得到的一个信息是:异或结果中为 1 的位置,即是目标数字之间的不同位。借助这一信息,选取其中任意一个不同位作为依据,就可以将这两个目标数字分开,使得分开后的最终异或结果即是两个目标数字分别与 0 异或的结果,也就得到了两个目标数字本身的值。
完整代码:
1 | class Solution { |
⚪ 2021.10.29 (335. 路径交叉)
🔴 未做
🟠 2021.10.28 (869. 重新排序得到 2 的幂)
题目
给定正整数 N ,我们按任何顺序(包括原始顺序)将数字重新排序,注意其前导数字不能为零。
如果我们可以通过上述方式得到 2 的幂,返回 true;否则,返回 false。
示例 1:
1 | 输入:10 |
示例 2:
1 | 输入:16 |
示例 3:
1 | 输入:24 |
示例 4:
1 | 输入:46 |
提示:
1 <= N <= 10^9
题解
由于指数爆炸现象的存在,不难想到在题目 1 <= N <= 10^9 的数据限制下,所有可能的 2 的幂的数量是很少的,又输入 n 能够随意排序,进而不需要考虑数字的顺序问题,其实是降低了难度的。
具体操作上,只需先提前准备好所有可能的 2 的幂,然后将这些 2 的幂的值作为文本,将每一位数字按固定的规则排好序(如从小到大排序)存放在一个待查列表 legalList 中。这样一来,对于输入的 n 只要也按这个规则排好序,排序后的结果若在 legalList 中存在,则说明这组数字能够按其在 legalList 创建时的“打乱”(排序)操作逆向复原得到一个 2 的幂,若不存在于 legalList 中,自然也就不存在复原出 2 的幂的排列操作。
完整代码:
1 | class Solution { |

🔴 2021.10.27 (301. 删除无效的括号)
题目
给你一个由若干括号和字母组成的字符串 s ,删除最小数量的无效括号,使得输入的字符串有效。
返回所有可能的结果。答案可以按 任意顺序 返回。
示例 1:
1 | 输入:s = "()())()" |
示例 2:
1 | 输入:s = "(a)())()" |
示例 3:
1 | 输入:s = ")(" |
提示:
1 <= s.length <= 25s由小写英文字母以及括号'('和')'组成s中至多含20个括号
题解
因为每一个半括号都有可能被删除,因此首先考虑用回溯遍历解决本题。在每一个下标处,如果对应字符是括号,那么就可以选择保留,也可以选择不保留,直到字符串的最后一个字符扫描完毕,检查其是否构成一个有效的串,
如何检查其括号是否有效呢?非常简单,只需设置一个偏移变量 bias 记录左括号的盈余状态
- 若扫描并加入了一个左括号,则
bias++ - 若扫描并加入了一个右括号,则
bias--
那么显然在扫描的途中,一旦出现 bias < 0 则说明串已经出现非法状态,必然无效,不需要再往后扫描了,此时可以剪枝。而在整个串扫描完毕后,检查 bias 的值即可,若为 0 则说明没有左括号盈余,也就是有效,否则无效。
不过这样的遍历耗时还算非常严重的,经过分析思考不难发现仍有可剪枝的地方。由于题目要求删除最小数量的括号,这就给优化提供了一条思路,即在 DFS 的过程中记录前面已经删除的括号数量,若在递归过程中删除的括号数量已经大于了之前产生过的有效串所删除的括号数,那么就不必再往深处遍历了,就算再找到有效串,也必然不是删除最小数量括号的串,不能作为结果之一。
完整代码:
1 | class Solution { |
🟢 2021.10.26 (496. 下一个更大元素 I)
题目
给你两个 没有重复元素 的数组 nums1 和 nums2 ,其中nums1 是 nums2 的子集。
请你找出 nums1 中每个元素在 nums2 中的下一个比其大的值。
nums1 中数字 x 的下一个更大元素是指 x 在 nums2 中对应位置的右边的第一个比 x 大的元素。如果不存在,对应位置输出 -1 。
示例 1:
1 | 输入: nums1 = [4,1,2], nums2 = [1,3,4,2]. |
示例 2:
1 | 输入: nums1 = [2,4], nums2 = [1,2,3,4]. |
提示:
1 <= nums1.length <= nums2.length <= 10000 <= nums1[i], nums2[i] <= 10^4nums1和nums2中所有整数 互不相同nums1中的所有整数同样出现在nums2中
题解
首先最简单最直接的思路,就是遍历 nums1 中的元素,对于 nums1 中的元素,去 nums2 中从头遍历(因为 nums2 无序)寻找它的相应位置,在找到相应位置后,在其位置后方继续寻找到第一个比它大的元素,存放在结果数组中的相应位置即可。
可以注意到,nums1 和 nums2 的长度均小于 $10^3$ 数量级,因此通过 $O(n^2)$ 的暴搜算法时间也能控制在 $10^6$ 以内,故是够能顺利 AC 的。
完整代码:
1 | class Solution { |

不过这样显然是比较低效率的做法,在 nums2 中寻找 nums1[i] 的过程中,其实中途遍历了很多其它元素,而这些被遍历过的元素在后面作为 nums1[i] 的时候,又要重头来找,导致时间复杂度来到平方级别。为了避免重复搜索,可以牺牲 $O(n)$ 的空间复杂度,预先建立 nums[2] 中值和下标的对应关系,这样就省去了对于 nums1 中的每个元素都要重新遍历 $nums2$ 的冗余搜索。
优化版完整代码:
1 | class Solution { |

🟠 2021.10.25 (240. 搜索二维矩阵 II)
题目
编写一个高效的算法来搜索 m x n 矩阵 matrix 中的一个目标值 target 。该矩阵具有以下特性:
- 每行的元素从左到右升序排列。
- 每列的元素从上到下升序排列。
示例 1:
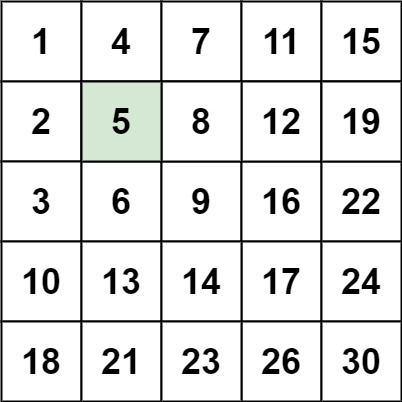
1 | 输入:matrix = [[1,4,7,11,15],[2,5,8,12,19],[3,6,9,16,22],[10,13,14,17,24],[18,21,23,26,30]], target = 5 |
示例 2:
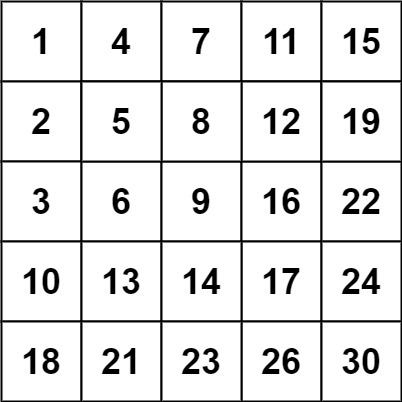
1 | 输入:matrix = [[1,4,7,11,15],[2,5,8,12,19],[3,6,9,16,22],[10,13,14,17,24],[18,21,23,26,30]], target = 20 |
提示:
m == matrix.lengthn == matrix[i].length1 <= n, m <= 300-10^9 <= matrix[i][j] <= 10^9- 每行的所有元素从左到右升序排列
- 每列的所有元素从上到下升序排列
-10^9 <= target <= 10^9
题解
首先可以按照无序数组遍历,从左到右,从上到下的次序,但是相应的时间复杂度就为 $O(mn)$,为了充分利用 matrix 每行递增、每列递增的特性,不难发现只需以自右向左,自上向下的次序,就可以实现 $O(m+n)$ 的搜索。
在从左到右,从上到下的遍历情况下,若当前元素的值小于目标值,那么并不能够确定目标值就在当前列下,因为后一列的元素也可能小于目标值,也就是说按照检索可能列的方式,会出现多个可能列的情况,进而无法单向遍历,若该列没有找到目标值,就必然要回溯检查下一列,进而沦为了 $O(mn)$ 的情况。
但按照自右向左,自上向下的次序,若当前元素的值大于目标值,那么是可以绝对确定目标值一定不在当前列的,因此可以不回溯地将搜索列向左移动一列。同时,若当前元素值小于目标值,同样可以确定目标值一定不在当前行,因此可以不回溯地将搜索行向下移动一行,进而确保每一步检查移动都必然向着正确的方向在走,不存在回溯,做到 $O(m+n)$ 的时间复杂度。
完整代码:
1 | class Solution { |
⚪ 2021.10.24 (638. 大礼包)
🟠 未解决
🟢 2021.10.23 (492. 构造矩形)
题目
作为一位web开发者, 懂得怎样去规划一个页面的尺寸是很重要的。 现给定一个具体的矩形页面面积,你的任务是设计一个长度为 L 和宽度为 W 且满足以下要求的矩形的页面。要求:
1 | 1. 你设计的矩形页面必须等于给定的目标面积。 |
你需要按顺序输出你设计的页面的长度 L 和宽度 W。
示例:
1 | 输入: 4 |
说明:
- 给定的面积不大于 10,000,000 且为正整数。
- 你设计的页面的长度和宽度必须都是正整数。
题解
由要求1和2可知,矩形宽度最大不可能超过 $\sqrt{area}$,因此只需遍历区间 $[1,\;\lfloor\sqrt{area}\rfloor]$ 内可能的宽度,然后记录长宽差值最小的那一对长宽即可。所谓“可能的宽度,即宽度对应的长度也是整数,即使用面积对宽度求取的余数为零即可。
完整代码:
1 | class Solution { |
但是不难发现,只有尽可能大的宽度才能对应尽可能小的长宽差值,那么最小的长宽差值必然是由最大的有效宽度确定。据此将遍历的方向调换,这样找到的第一对有效长宽就是对应本题的答案了,虽然空间复杂度也是 $O(n)$,但求解效率却显然要远高于之前的代码。
调换遍历策略后的完整代码:
1 | class Solution { |
🟠 2021.10.22 (229. 求众数 II)
题目
给定一个大小为 n 的整数数组,找出其中所有出现超过 ⌊ n/3 ⌋ 次的元素。
示例 1:
1 | 输入:[3,2,3] |
示例 2:
1 | 输入:nums = [1] |
示例 3:
1 | 输入:[1,1,1,3,3,2,2,2] |
提示:
1 <= nums.length <= 5 * 10^4-10^9 <= nums[i] <= 10^9
题解
借助 HashMap 统计所有数字的出现次数,若出现次数大于 $\frac{1}{3}$ 则加入结果 List 中即可。
完整代码
1 | class Solution { |
🟢 2021.10.21 (66. 加一)
题目
给定一个由 整数 组成的 非空 数组所表示的非负整数,在该数的基础上加一。
最高位数字存放在数组的首位, 数组中每个元素只存储单个数字。
你可以假设除了整数 0 之外,这个整数不会以零开头。
示例 1:
1 | 输入:digits = [1,2,3] |
示例 2:
1 | 输入:digits = [4,3,2,1] |
示例 3:
1 | 输入:digits = [0] |
提示:
1 <= digits.length <= 1000 <= digits[i] <= 9
题解
按照正常的加法思路,从低位加一,然后检查进位,若有进位就将低位置零,并检查高一位加一后是否溢出,以此类推。特别地,考虑到进位可能产生的整个数字位数增加的情况,将每位的处理结果先添加到 List 中,最后将 List 映射转换回整型数组返回,这样可以方便地在最高位产生进位时,容易地向数字最高位前增加一位新数字。
完整代码:
1 | class Solution { |

⚪ 2021.10.20 (453. 最小操作次数使数组元素相等)
🟢 未做
🟠 2021.10.19 (211. 添加与搜索单词)
题目
请你设计一个数据结构,支持 添加新单词 和 查找字符串是否与任何先前添加的字符串匹配 。
实现词典类 WordDictionary :
WordDictionary()初始化词典对象void addWord(word)将word添加到数据结构中,之后可以对它进行匹配- bool search(word) 如果数据结构中存在字符串与 word 匹配,则返回 true ;否则,返回 false 。word 中可能包含一些 ‘.’ ,每个 . 都可以表示任何一个字母。
示例:
1 | 输入: |
提示:
1 <= word.length <= 500addWord中的word由小写英文字母组成search中的word由 ‘.’ 或小写英文字母组成- 最多调用
50000次addWord和search
题解
首先容易想到最直接的遍历方法,直接用一个 List 存储添加的 word,在搜索时,首先检查搜索 word 和当前遍历的 List 中的单词的长度,若两者长度不同,则必然不匹配,可以直接跳过。若两者长度相同,则开始逐字母比较两个单词是否相匹配,特别地,对于搜索的 word 中为 . 的位,认为其匹配。
不过这样做在提交后会超时。为了减少遍历的数据量,可以通过以 word 的长度为依据,使用多个 List 存储的办法来实现。如待搜索的的单词长度为 n,那么只需要遍历长度为 n 的单词的 List 即可,而不需要在添加过的所有单词中遍历,进而优化了时间开销。为了实现 List 的按长度分类,使用 HashMap<Integer, List<String>> 即可。
完整代码:
1 | class WordDictionary { |

🟢 2021.10.18 (476. 数字的补数)
题目
给你一个 正 整数 num ,输出它的补数。补数是对该数的二进制表示取反。
示例 1:
1 | 输入:num = 5 |
提示:
- 给定的整数
num保证在 32 位带符号整数的范围内。 num >= 1- 你可以假定二进制数不包含前导零位。
- 本题与 1009 https://leetcode-cn.com/problems/complement-of-base-10-integer/ 相同
题解
非常简单,很容易想到直接取反后会导致符号位的变化,由于题给 num 必是正数,因此取反后符号位必是 1,为了得到正确结果,只需在取反后将符号位置 0 即可。为了找到符号位的位置,显然可以构造一个高位 1,将高位 1 不断右移,从高位到低位找到所给 num 的最高位 1,那么其符号位就在对应最高位 1 的左移一位处。
完整代码:
1 | class Solution { |
⚪ 2021.10.17
🔴 事务繁忙,无空做
⚪ 2021.10.16
🔴 事务繁忙,无空做
🟠 2021.10.15 (38. 外观数列)
题目
给定一个正整数 n ,输出外观数列的第 n 项。
「外观数列」是一个整数序列,从数字 1 开始,序列中的每一项都是对前一项的描述。
你可以将其视作是由递归公式定义的数字字符串序列:
countAndSay(1) = "1"countAndSay(n)是对countAndSay(n-1)的描述,然后转换成另一个数字字符串。
前五项如下:
1 | 1. 1 |
要 描述 一个数字字符串,首先要将字符串分割为 最小 数量的组,每个组都由连续的最多 相同字符 组成。然后对于每个组,先描述字符的数量,然后描述字符,形成一个描述组。要将描述转换为数字字符串,先将每组中的字符数量用数字替换,再将所有描述组连接起来。
例如,数字字符串 "3322251" 的描述如下图:

示例 1:
1 | 输入:n = 1 |
示例 2:
1 | 输入:n = 4 |
提示:
1 <= n <= 30
题解
以字符串String res = "1" 为初始状态,按照题意以 res = countString(res) 规则递归地“读”出字符串即可。
完整代码:
1 | class Solution { |
🟢 2021.10.14 (剑指 Offer II 069. 山峰数组的顶部)
题目
略
题解
从头开始按顺序找到第一个比后一个数大的数字下标,即是山峰位置。此办法需要遍历数组,故时间复杂度为 $O(n)$。
完整代码:
1 | class Solution { |
🟢 2021.10.13 (412. Fizz Buzz)
题目
写一个程序,输出从 1 到 n 数字的字符串表示。
\1. 如果 n 是3的倍数,输出“Fizz”;
\2. 如果 n 是5的倍数,输出“Buzz”;
\3. 如果 n 同时是3和5的倍数,输出 “FizzBuzz”。
示例:
1 | n = 15, |
题解
按要求写即可,完整代码:
1 | class Solution { |

🟠 2021.10.12 (29. 两数相除)
题目
给定两个整数,被除数 dividend 和除数 divisor。将两数相除,要求不使用乘法、除法和 mod 运算符。
返回被除数 dividend 除以除数 divisor 得到的商。
整数除法的结果应当截去(truncate)其小数部分,例如:truncate(8.345) = 8 以及 truncate(-2.7335) = -2
示例 1:
1 | 输入: dividend = 10, divisor = 3 |
示例 2:
1 | 输入: dividend = 7, divisor = -3 |
提示:
- 被除数和除数均为 32 位有符号整数。
- 除数不为 0。
- 假设我们的环境只能存储 32 位有符号整数,其数值范围是 [−2^31, 2^31 − 1]。本题中,如果除法结果溢出,则返回 2^31 − 1。除数不为 0。
题解
使用减法的定义,将被除数不断减去除数,看看够完整减去几次,除的商就是几。不过这题坑的地方是溢出的情况,如 $-2^{31}$ 作为除数,$-1$ 作为被除数,结果就溢出了,此外也存在计算中途的溢出情况,也都是 $-2^{31}$ 作为除数的时候的情况。
完整代码:
1 | class Solution { |
🔴 2021.10.11 (273. 整数转换英文表示)
题目
将非负整数 num 转换为其对应的英文表示。
示例 1:
1 | 输入:num = 123 |
示例 2:
1 | 输入:num = 12345 |
示例 3:
1 | 输入:num = 1234567 |
示例 4:
1 | 输入:num = 1234567891 |
提示:
0 <= num <= 231 - 1
题解
没有任何技巧,就遍历各种位数各种情况各种表示摁写,憨憨一样写的跟坨啥似的,反正 AC 了。
完整代码:
1 | class Solution { |
🟢 2021.10.10 (441. 排列硬币)
题目
你总共有 n 枚硬币,并计划将它们按阶梯状排列。对于一个由 k 行组成的阶梯,其第 i 行必须正好有 i 枚硬币。阶梯的最后一行 可能 是不完整的。
给你一个数字 n ,计算并返回可形成 完整阶梯行 的总行数。
你一个数字 n ,计算并返回可形成 完整阶梯行 的总行数。
示例 1:
1 | 输入:n = 5 |
提示:
1 <= n <= 2^31 - 1
题解
一元二次方程送分题。令
要使得 $k$ 的取值恰好为小于等于 $n$ 的整数,那么显然
完整代码:
1 | class Solution { |

在编码的时候遇到了一个小插曲,测试的时候有些用例会溢出输出 0,原因是输入数据的取值范围为 $1 \leq n \leq 2^{31} - 1$,而 $n$ 是整型的,因此 $8\times n$ 的上限是 $2^{33} - 8$,依旧作为整型存储的话自然可能会溢出,只需在乘以 $8$ 之前将 $n$ 转为 long 型,使得乘出来的结果也是 long 就行了。
⚪ 2021.10.09 (352. 将数据流变为多个不相交区间)
🔴 不会,也没看题解,没空
🟠 2021.10.08 (187. 重复的DNA序列)
题目
所有 DNA 都由一系列缩写为 'A','C','G' 和 'T' 的核苷酸组成,例如:"ACGAATTCCG"。在研究 DNA 时,识别 DNA 中的重复序列有时会对研究非常有帮助。
编写一个函数来找出所有目标子串,目标子串的长度为 10,且在 DNA 字符串 s 中出现次数超过一次。
示例 1:
1 | 输入:s = "AAAAACCCCCAAAAACCCCCCAAAAAGGGTTT" |
示例 2:
1 | 输入:s = "AAAAAAAAAAAAA" |
提示:
0 <= s.length <= 105s[i]为'A'、'C'、'G'或'T'
题解
从头开始遍历所有以 s[i] 为起点长度为 10 的子串 ss,对遍历过程中的所有字串,向后嵌套遍历是否存在以 s[i+j] 为起点长度为 10 与 ss 相同的字串,即为答案,加入答案 List 中,一通操作猛如虎,然后 TLE。
朴素 $O(n^2)$ 超时解法:
1 | class Solution { |
如果这题用 JavaScript 做的话很容易想到对象映射的方式实现 $O(n)$,但无奈对 Java 实在不熟。。不知道在 Java 中怎么实现自己的想法,经过了解学习后知道了 Java 中有个存储键值对的 HashMap<> 泛型类,看来是可以用这个实现的。
经过尝试和调试,成功 AC 了,算是通过这题对 Java 类库有点收获了。
完整代码:
1 | class Solution { |

🟢 2021.10.07 (434. 字符串中的单词数)
题目
统计字符串中的单词个数,这里的单词指的是连续的不是空格的字符。
请注意,你可以假定字符串里不包括任何不可打印的字符。
示例:
1 | 输入: "Hello, my name is John" |
题解
设置一个状态记录器 start,遍历字符串中的字符,当字符为非空格时,将状态 start 记录为 true,当字符为空格时,如果 start 为 true,则说明一个单词结束,将计数器自增,并把 start 置回 false,等待下一个单词。
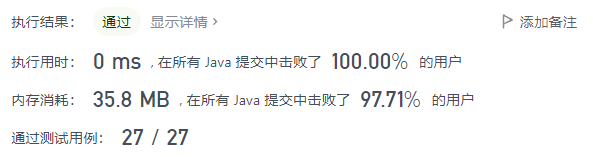
1 | class Solution { |
🟢 2021.10.06 (414. 第三大的数)
题目
给你一个非空数组,返回此数组中 第三大的数 。如果不存在,则返回数组中最大的数。
示例 1:
1 | 输入:[3, 2, 1] |
示例 2:
1 | 输入:[1, 2] |
示例 3:
1 | 输入:[2, 2, 3, 1] |
提示:
1 <= nums.length <= 10^4-2^31 <= nums[i] <= 2^31 - 1
题解
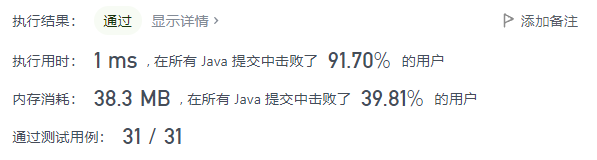
使用插入排序来维护一个长度为 3 的排序数组即可,时间复杂度为 $O(n)$,空间复杂度为 $O(1)$。因为研一上半学期的 Java 课程有一项考核点是用 Java 做 20 道 LC,所以之后也写写 Java 了,完整代码:
1 | class Solution { |
🟠 2021.10.05 (284. 窥探迭代器)
题目
请你设计一个迭代器,除了支持 hasNext 和 next 操作外,还支持 peek 操作。
实现 PeekingIterator 类:
PeekingIterator(int[] nums)使用指定整数数组nums初始化迭代器。int next()返回数组中的下一个元素,并将指针移动到下个元素处。bool hasNext()如果数组中存在下一个元素,返回true;否则,返回false。int peek()返回数组中的下一个元素,但 不 移动指针。
题解
没什么好写的,完整代码:
1 | /** |
🟢 2021.10.04 (482. 密钥格式化)
题目
有一个密钥字符串 S ,只包含字母,数字以及 ‘-‘(破折号)。其中, N 个 ‘-‘ 将字符串分成了 N+1 组。
给你一个数字 K,请你重新格式化字符串,使每个分组恰好包含 K 个字符。特别地,第一个分组包含的字符个数必须小于等于 K,但至少要包含 1 个字符。两个分组之间需要用 ‘-‘(破折号)隔开,并且将所有的小写字母转换为大写字母。
给定非空字符串 S 和数字 K,按照上面描述的规则进行格式化。
示例 1:
1 | 输入:S = "5F3Z-2e-9-w", K = 4 |
示例 2:
1 | 输入:S = "2-5g-3-J", K = 2 |
提示:
- S 的长度可能很长,请按需分配大小。K 为正整数。
- S 只包含字母数字(a-z,A-Z,0-9)以及破折号’-‘
- S 非空
题解
显然,完整代码:
1 | /** |
🟠 2021.10.03 (166. 分数到小数)
题目
给定两个整数,分别表示分数的分子 numerator 和分母 denominator,以 字符串形式返回小数 。
如果小数部分为循环小数,则将循环的部分括在括号内。
如果存在多个答案,只需返回 任意一个 。
对于所有给定的输入,保证 答案字符串的长度小于 $10^4$ 。
示例 1:
1 | 输入:numerator = 1, denominator = 2 |
示例 2:
1 | 输入:numerator = 2, denominator = 1 |
示例 3:
1 | 输入:numerator = 2, denominator = 3 |
提示:
-2^31 <= numerator, denominator <= 2^31 - 1denominator != 0
题解
按除法规则进行除,并记录历史余数,如果余数为 0,说明计算结束,如果余数已经出现过了,说明结果是无限循环小数,可以终止计算,且循环是从余数第一次产生位置的商的后一位开始(后一位是因为,余数是上一次商后的做差结果,是用来给下一次商的,故循环从下一次商开始)。
按照这个模型编码,完整代码:
1 | /** |
🟢 2021.10.02 (405. 数字转换为十六进制数)
题目
给定一个整数,编写一个算法将这个数转换为十六进制数。对于负整数,我们通常使用 补码运算 方法。
注意:
- 十六进制中所有字母(
a-f)都必须是小写。 - 十六进制字符串中不能包含多余的前导零。如果要转化的数为0,那么以单个字符
'0'来表示;对于其他情况,六进制字符串中的第一个字符将不会是0字符。 - 给定的数确保在32位有符号整数范围内。
- 不能使用任何由库提供的将数字直接转换或格式化为十六进制的方法。
示例 1:
1 | 输入: |
示例 2:
1 | 输入: |
题解
常规的解法是,若数字为负数,那么加上 $2^{32}$ 的偏移量(转为补码),然后不断对 16 取余数,小于 10 的转换为 '0' ~ '9',大于 10 的转换为 a ~ f 即可。
另外,更加简洁的解法是利用位运算,因为位运算在计算机底层会自动解释为补码运算,因此使用位运算就完全不用管负数补码的事了,直接每四位转十六进制就完事,同时这也是 LC 给的官解。完整代码:
1 | /** |
不过,既然有这个机会,就重新复习以下机组原码反码补码二进制十六进制转换这些内容。我们首先将数字转成二进制原码,再将原码转为补码,然后对补码按每四位编码为十六进制数,最后切掉前导零,以字符串形式返回即可,就是写起来有点麻烦。
完整代码:
1 | /** |
🟢 2021.10.01 (1436. 旅行终点站)
国庆快乐!🎉🎉🎉
题目
给你一份旅游线路图,该线路图中的旅行线路用数组 paths 表示,其中 paths[i] = [cityAi, cityBi] 表示该线路将会从 cityAi 直接前往 cityBi 。请你找出这次旅行的终点站,即没有任何可以通往其他城市的线路的城市。
题目数据保证线路图会形成一条不存在循环的线路,因此恰有一个旅行终点站。
示例 1:
1 | 输入:paths = [["London","New York"],["New York","Lima"],["Lima","Sao Paulo"]] |
示例 2:
1 | 输入:paths = [["A","Z"]] |
提示:
1 <= paths.length <= 100paths[i].length == 21 <= cityAi.length, cityBi.length <= 10cityAi != cityBi- 所有字符串均由大小写英文字母和空格字符组成。
题解
首先是最直觉的递归,不断寻找下一站,最终找到终点站返回,递归版完整代码:
1 | var destCity = function(paths) { |
这样虽然能 AC,但是不够优雅,每次从头开始遍历 paths 导致 $O(n^2)$ 的时间复杂度,并且递归开栈也造成了 $O(n)$ 的空间复杂度。我们不妨首先遍历一次 paths,在遍历过程中将源地和目的地构造成一对键值对,这样就方便搜索了,虽然还是 $O(n)$ 的空间复杂度,但时间复杂度从 $O(n^2)$ 降到了 $O(n)$。
完整代码:
1 | var destCity = function(paths) { |
🟠 2021.09.30 (223. 矩形面积)
题目
给你 二维 平面上两个 由直线构成的 矩形,请你计算并返回两个矩形覆盖的总面积。
每个矩形由其 左下 顶点和 右上 顶点坐标表示:
- 第一个矩形由其左下顶点
(ax1, ay1)和右上顶点(ax2, ay2)定义。 - 第二个矩形由其左下顶点
(bx1, by1)和右上顶点(bx2, by2)定义。
示例 1:
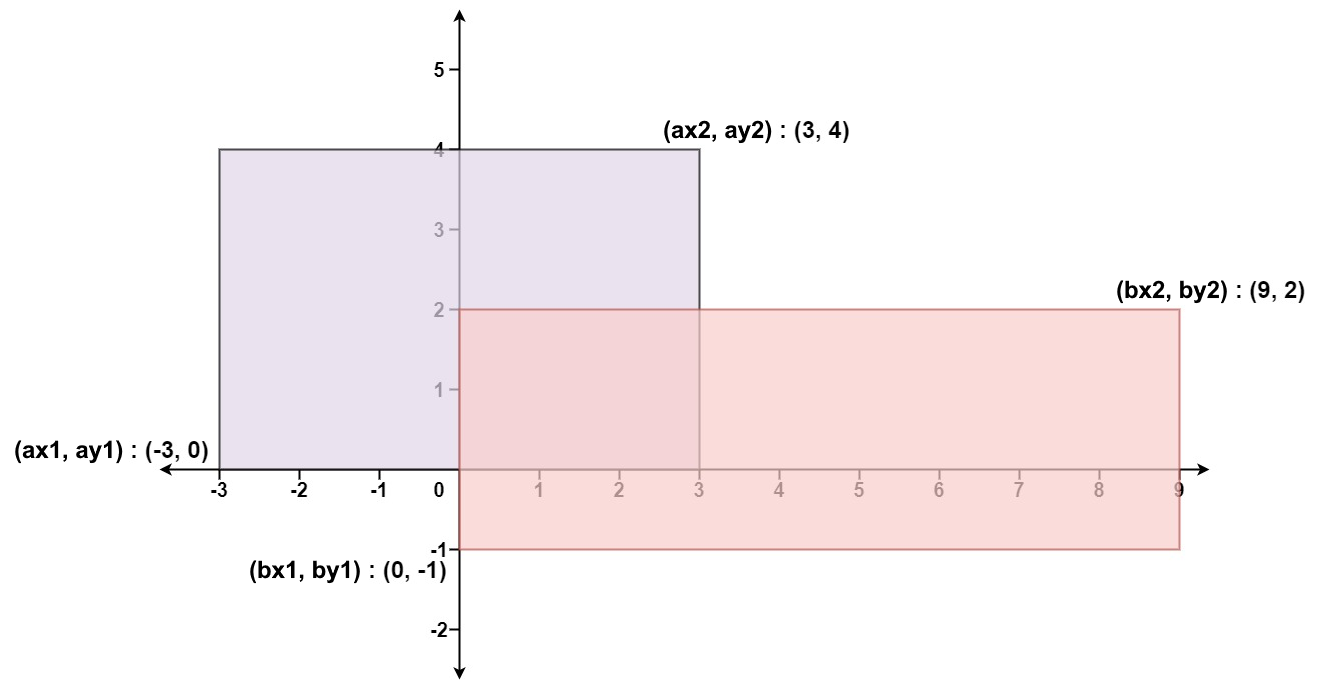
1 | 输入:ax1 = -3, ay1 = 0, ax2 = 3, ay2 = 4, bx1 = 0, by1 = -1, bx2 = 9, by2 = 2 |
提示:
首先计算两个矩形的面积之和
1 | var all = (ax2 - ax1) * (ay2 - ay1) + (bx2 - bx1) * (by2 - by1); |
然后考虑重合部分,特别地,当一个矩形的右边在另一个矩形的左侧等情况时,两个矩形是没有重合部分的,即:
1 | if(ax2 <= bx1 || ax1 >= bx2 || ay1 >= by2 || ay2 <= by1) return all; |
对于重合部分,只需要找到重合矩形的左上角和右下角即可,该坐标不难计算,详见完整代码:
1 | var computeArea = function(ax1, ay1, ax2, ay2, bx1, by1, bx2, by2) { |
🔴 2021.09.29 (517. 超级洗衣机)
题目
假设有 n 台超级洗衣机放在同一排上。开始的时候,每台洗衣机内可能有一定量的衣服,也可能是空的。
在每一步操作中,你可以选择任意 m (1 <= m <= n) 台洗衣机,与此同时将每台洗衣机的一件衣服送到相邻的一台洗衣机。
给定一个整数数组 machines 代表从左至右每台洗衣机中的衣物数量,请给出能让所有洗衣机中剩下的衣物的数量相等的 最少的操作步数 。如果不能使每台洗衣机中衣物的数量相等,则返回 -1 。
示例 1:
1 | 输入:machines = [1,0,5] |
示例 2:
1 | 输入:machines = [0,3,0] |
提示:
n == machines.length1 <= n <= 1040 <= machines[i] <= 105
题解
一天学完了 JS,接下来要两天速通 Vue 了,没空写题解辽。
$O(n^3)$ 暴力超时代码(困难题果然还是不能暴力的呢):
1 | /** |
$O(n)$ AC 完整代码:
1 | /** |
🟠 2021.09.28 (437. 路径总和 III)
题目
给定一个二叉树的根节点 root ,和一个整数 targetSum ,求该二叉树里节点值之和等于 targetSum 的 路径 的数目。
路径 不需要从根节点开始,也不需要在叶子节点结束,但是路径方向必须是向下的(只能从父节点到子节点)。
示例 1:
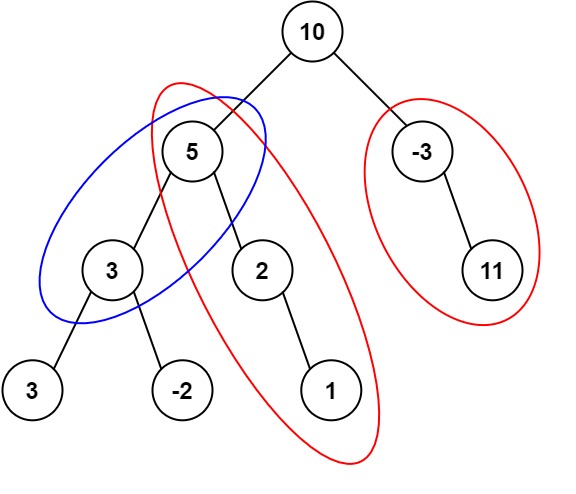
1 | 输入:root = [10,5,-3,3,2,null,11,3,-2,null,1], targetSum = 8 |
题解
暴力解,双重遍历。遍历树的所有节点,并对每个节点遍历以该节点为 root 的树到所有节点的路径 val ,对于路径 val 为 targetSum 的情况,自增全局计数器 res。
完整代码:
1 | var res = 0; |

⚪ 2021.09.27 (639. 解码方法 II)
🔴 速通 JavaScript 去了,未做
⚫ 2021.09.26 (371. 两整数之和)
🟠 未更新
🟠 2021.09.25 (583. 两个字符串的删除操作)
题目
给定两个单词 word1 和 word2,找到使得 word1 和 word2 相同所需的最小步数,每步可以删除任意一个字符串中的一个字符。
示例:
1 | 输入: "sea", "eat" |
提示:
- 给定单词的长度不超过500。
- 给定单词中的字符只含有小写字母。
题解
本题不难想到转化为求解最长公共子序列长度问题。
最长公共子序列,可以用动态规划来解。定义 dp[i, j] 表示word1 前 i 个字符和 word2 前 j 个字符的最长公共子序列长度。那么则有如下状态转移:
- 若
word1[i] == word2[j]则显然dp[i, j] = dp[i-1, j-1] + 1,表示将当前比较的位加入到前一次的最长公共子序列长度中; - 若
word1[i] == word2[j],则继承两种上一状态中长度较长的那个长度作为最长长度,即dp[i, j] = Max(dp[i-1, j], dp[i, j-1])。
完整代码:
1 | public class Solution { |

🟠 2021.09.24 (430. 扁平化多级双向链表)
题目
多级双向链表中,除了指向下一个节点和前一个节点指针之外,它还有一个子链表指针,可能指向单独的双向链表。这些子列表也可能会有一个或多个自己的子项,依此类推,生成多级数据结构,如下面的示例所示。
给你位于列表第一级的头节点,请你扁平化列表,使所有结点出现在单级双链表中。
示例 1:
输入:head = [1,2,3,4,5,6,null,null,null,7,8,9,10,null,null,11,12]
输出:[1,2,3,7,8,11,12,9,10,4,5,6]
解释:输入的多级列表如下图所示:
扁平化后的链表如下图:
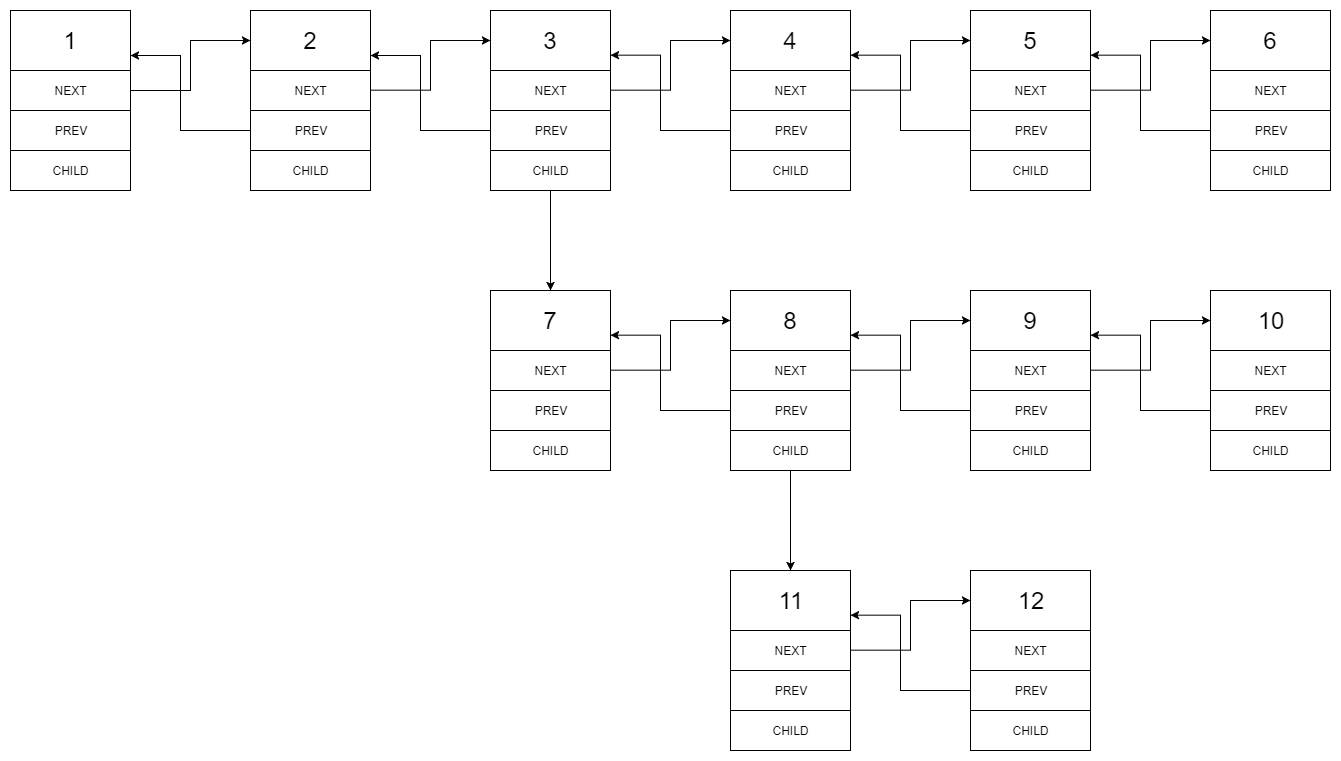

示例 2:
输入:head = [1,2,null,3]
输出:[1,3,2]
解释:输入的多级列表如下图所示:
1—-2—-NULL
|
3—-NULL
提示:
- 节点数目不超过 1000
1 <= Node.val <= 10^5
题解
朴素的办法,遍历,遇到有子节点的,就找到子节点那层的最后一个节点,然后捏住首位将整个子节点这层插上来。缺点是每个子层会被遍历两次(找子层尾节点遍历一次,并入住层后继续遍历就被重复遍历了),所以复杂度是 $O(n^2)$,完整代码:
1 | public class Solution { |
但更好的办法是递归,这样可以做到 $O(n)$ 的时间复杂度。完整代码:
1 | public class Solution { |
🟢 2021.09.23 (326. 3的幂)
题目
给定一个整数,写一个函数来判断它是否是 3 的幂次方。如果是,返回 true ;否则,返回 false 。
整数 n 是 3 的幂次方需满足:存在整数 x 使得 n == 3x
示例 1:
1 | 输入:n = 27 |
示例 2:
1 | 输入:n = 0 |
题解
直接递归之。完整代码:
1 | public class Solution { |
🟠 2021.09.22 (725. 分隔链表)
题目
给你一个头结点为 head 的单链表和一个整数 k ,请你设计一个算法将链表分隔为 k 个连续的部分。
每部分的长度应该尽可能的相等:任意两部分的长度差距不能超过 1 。这可能会导致有些部分为 null 。
这 k 个部分应该按照在链表中出现的顺序排列,并且排在前面的部分的长度应该大于或等于排在后面的长度。
返回一个由上述 k 部分组成的数组。
示例 1:
1 | 输入:head = [1,2,3], k = 5 |
示例 2:

1 | 输入:head = [1,2,3,4,5,6,7,8,9,10], k = 3 |
提示:
- 链表中节点的数目在范围
[0, 1000] 0 <= Node.val <= 10001 <= k <= 50
题解
又是直觉题。显然计算 链表长度 / 分割数量 即是可被均分的每个 section 中的基础节点数量,而 链表长度 % 分割数量 即是均分后剩下来的节点数,由于要求 “任意两部分的长度差距不能超过 1”并且“排在前面的部分的长度应该大于或等于排在后面的长度”,因此将剩下的节点数往前面的 section 中加即可,每个 section 塞一个节点数。
如初始链表有 17 个节点,要均分成 k = 3 份(3 个 section),那么每个 section 就有 17 / 3 = 5 个基础节点个数,不过这样就会多出来 17 % 3 = 2 个节点,只要往前 2 个 section 中多放一个节点即可得到 6 6 5 的正确分割长度。
完整代码:
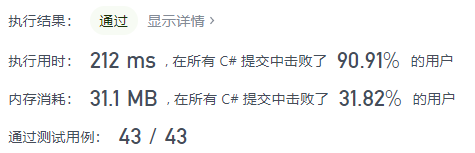
1 | public class Solution { |
🟢 2021.09.21 (58. 最后一个单词的长度)
题目
给你一个字符串 s,由若干单词组成,单词前后用一些空格字符隔开。返回字符串中最后一个单词的长度。
单词 是指仅由字母组成、不包含任何空格字符的最大子字符串。
示例 1:
1 | 输入:s = "Hello World" |
示例 2:
1 | 输入:s = " fly me to the moon " |
提示:
1 <= s.length <= 104s仅有英文字母和空格' '组成s中至少存在一个单词
题解
中秋快乐!🎑
直接倒着找到最后一个单词的最后一个字母,然后触发一个 start 触发器开始记录长度,直至记录到最后一个单词前的第一个空格返回记录的长度即可。
完整代码:
1 | public class Solution { |
当然,也可以直接用库函数一行代码解决:
1 | public class Solution { |
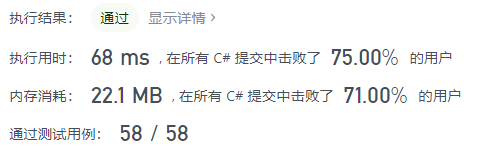
🟠 2021.09.20 (673. 最长递增子序列的个数)
题目
给定一个未排序的整数数组,找到最长递增子序列的个数。
示例 1:
1 | 输入: [1,3,5,4,7] |
示例 2:
1 | 输入: [2,2,2,2,2] |
注意: 给定的数组长度不超过 2000 并且结果一定是32位有符号整数。
题解
因为还没有学动态规划,因此最先想到的还是暴力遍历。定义函数 void FindNextNumber(int[] nums, int lastIndex, int currentIndex, int lastLength) 表示从上一数字找下一个可接的递增数字,其中对于 currentIndex 数大于 lastIndex 数的时候,表明可以接,将 lastLength +1 后继续往后找。
不过无论是否满足上面说的情况,都应该走一遍跳过当前数字的路径,确保不漏数。
如示例 1 的 [1,3,5,4,7],其中 5 可以接在 3 后面,但也应尝试跳过 5,才能捕获到 [1,3,4,7] 这一同样是最长递增的子序列。
1 | public class Solution { |
说了这么多,但这个暴力解法在序列合适的情况下是会超时的。。。
Update:
喵了一眼 LC 的题解,大概看懂了本题动态规划的思路。首先我们可以设置两个数组:
1 | // f[i]: the max length end with nums[i] |
其中 f[i] 记录以 nums[i] 为结尾的上升子序列的最大长度,g[i, k] 记录以 nums[i] 为结尾的上升子序列长度为 k 的序列个数。
初始时,数组 f 的值应全为 1,表示可以独立构成长度为 1 的上升子序列,进而 g[:,1] 也全为 1。
设置指针 i 从头往尾扫描,指针 j 从头扫描至 i-1,判断 nums[i] 能否接在 nums[j] 的后面,构成一个上升子序列。
1 | for(int i = 0; i < nums.Length; i++) |
若能构成上升子序列,那么说明以 nums[i] 结尾能够构成长度为 f[j] + 1 的递增子序列,并且构成的长度为 f[j] + 1 的子序列的个数是 nums[i] 同之前元素能构成长度为 f[j] + 1 的递增子序列的个数再加上被接上的 nums[j] 能构成长度为 f[j] 的子序列个数(如 1 3 5,5 能接在 3 后面,那么以 3 结尾能构成几个长度为 2 的序列,就也能以 5 结尾构成几个长度为 3 的序列)。同时,f[i] 应被更新为长度更长的 f[j] + 1,否则 f[i] 保持不变,确保存储的是能够构成的最长子序列长度。按照该逻辑,第 10 行处代码就为:
1 | g[i, f[j] + 1] += g[j, f[j]]; |
当整个扫描结束后,f 中就存储了分别以各个元素为结尾能构成的递增子序列的最长长度,g 中就存储了以各个元素为结尾能构成长度为 1 ~ nums.Length 的上升子序列的个数。
显然,要返回最长递增子序列的个数,只需要先用 f 找到最长的长度 k,然后从 g 中累加所有的 g[:,k] 即可。
完整代码:
1 | public class Solution { |
以原始序列 [1,3,5,4,7,4,8,9] 为例,运行结束后各变量的状态如下图所示,大体上,变量 g 从上至下,从左至右迭代,可供辅助手推理解。

🟠 2021.09.19 (650. 只有两个键的键盘)
题目
最初记事本上只有一个字符 'A' 。你每次可以对这个记事本进行两种操作:
Copy All(复制全部):复制这个记事本中的所有字符(不允许仅复制部分字符)。Paste(粘贴):粘贴 上一次 复制的字符。
给你一个数字 n ,你需要使用最少的操作次数,在记事本上输出 恰好 n 个 'A' 。返回能够打印出 n 个 'A' 的最少操作次数。
示例 1:
1 | 输入:3 |
示例 2:
1 | 输入:n = 1 |
提示:
1 <= n <= 1000
题解
首先第一直觉尝试了遍历操作,DFS配合剪枝,不过发现59及更大的奇数用例大部分超时了。
1 | /* DFS + 剪枝(部分奇数用例超时) */ |
有可能是剪枝不到位,或者数据量太大,此法不可行?总之在这个方向上没做出来。后看了提示之后想到了分解因式完全可以解决此题。
How many characters may be there in the clipboard at the last step if n = 3? n = 7? n = 10? n = 24?
以提示中的 n = 24 为例,由于 2、4、6、8、12 都是 24 的因数,而要使得操作步数最少,必然粘贴的字符数应该尽可能多,那么显然当取 12 个字符粘贴时能够实现更少的复制粘贴次数。因此,只需要寻找 n 的最大因数,然后不断进一步寻找其最大因数的最大的因数,直至最大因数(1除外)是自身时,说明此数是从最开始的一个 A 连续复制得到的。
完整代码:
1 | public class Solution { |
🟢 2021.09.18 (292. Nim 游戏)
题目
你和你的朋友,两个人一起玩 Nim 游戏:
- 桌子上有一堆石头。
- 你们轮流进行自己的回合,你作为先手。
- 每一回合,轮到的人拿掉 1 - 3 块石头。
- 拿掉最后一块石头的人就是获胜者。
假设你们每一步都是最优解。请编写一个函数,来判断你是否可以在给定石头数量为 n 的情况下赢得游戏。如果可以赢,返回 true;否则,返回 false 。
示例 1:
1 | 输入:n = 4 |
示例 2:
1 | 输入:n = 1 |
示例 3:
1 | 输入:n = 2 |
题解
由题目描述“你们每一步都是最优解”可以发现,示例1的必败情况就是本题的突破口。即双方都只需要将对手引导至剩余4块石头的局面,那么就是最优的取法。那么如何使对手剩下4块呢?其实只需将石头块数对4取余,即将4的倍数多余出来的石头拿走,这样对手就永远处于从4的倍数中取石头的境况中,而随着石头越取越少,倍数越来越小,最终对手必然剩下4的1倍,即4块石头。可见,胜负从开局石头数就已经定了。
完整代码:
1 | public class Solution { |
🟠 2021.09.17 (36. 有效的数独)
题目
请你判断一个 9x9 的数独是否有效。只需要 根据以下规则 ,验证已经填入的数字是否有效即可。
- 数字
1-9在每一行只能出现一次。 - 数字
1-9在每一列只能出现一次。 - 数字
1-9在每一个以粗实线分隔的3x3宫内只能出现一次。(请参考示例图)
数独部分空格内已填入了数字,空白格用 '.' 表示。
注意:
- 一个有效的数独(部分已被填充)不一定是可解的。
- 只需要根据以上规则,验证已经填入的数字是否有效即可。
示例 1:
输入:board =
[[“5”,”3”,”.”,”.”,”7”,”.”,”.”,”.”,”.”]
,[“6”,”.”,”.”,”1”,”9”,”5”,”.”,”.”,”.”]
,[“.”,”9”,”8”,”.”,”.”,”.”,”.”,”6”,”.”]
,[“8”,”.”,”.”,”.”,”6”,”.”,”.”,”.”,”3”]
,[“4”,”.”,”.”,”8”,”.”,”3”,”.”,”.”,”1”]
,[“7”,”.”,”.”,”.”,”2”,”.”,”.”,”.”,”6”]
,[“.”,”6”,”.”,”.”,”.”,”.”,”2”,”8”,”.”]
,[“.”,”.”,”.”,”4”,”1”,”9”,”.”,”.”,”5”]
,[“.”,”.”,”.”,”.”,”8”,”.”,”.”,”7”,”9”]]
输出:true
题解
根据数独有效性的三条规则,可以分别定义三个记忆变量,记录在某行处某数字是否出现过、在某列处某数字是否出现过、在某区域(九个粗格)内某数字是否出现过。遍历数独数字,若任三条中任一条出现过则数独无效,若遍历完所有格都没有出现过,则数独有效。
完整代码:
1 | public class Solution { |
🟠 2021.08.25 (797. 所有可能的路径)
题目
给你一个有 n 个节点的 有向无环图(DAG),请你找出所有从节点 0 到节点 n-1 的路径并输出(不要求按特定顺序)
二维数组的第 i 个数组中的单元都表示有向图中 i 号节点所能到达的下一些节点,空就是没有下一个结点了。
译者注:有向图是有方向的,即规定了 a→b 你就不能从 b→a 。
示例 1:
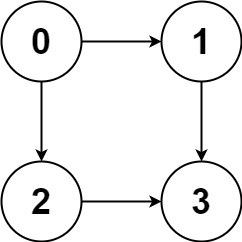
1 | 输入:graph = [[1,2],[3],[3],[]] |
示例 2:
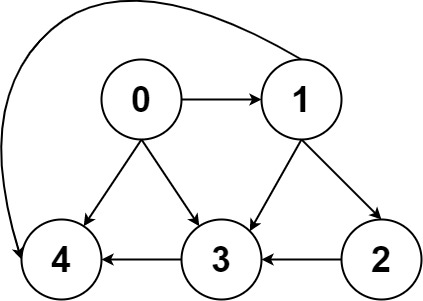
1 | 输入:graph = [[4,3,1],[3,2,4],[3],[4],[]] |
示例 3:
1 | 输入:graph = [[1],[]] |
提示:
n == graph.length2 <= n <= 150 <= graph[i][j] < ngraph[i][j] != i(即,不存在自环)graph[i]中的所有元素 互不相同- 保证输入为 有向无环图(DAG)
题解(回溯搜索)
此题数据量较小,且直接给了邻接表,直接进行深度优先遍历即可解决。完整代码:
1 | public class Solution { |

🟠 2021.08.24 (787. K 站中转内最便宜的航班)
题目
有 n 个城市通过一些航班连接。给你一个数组 flights ,其中 flights[i] = [from_i, to_i, price_i] ,表示该航班都从城市 from_i 开始,以价格 price_i 抵达 to_i。
现在给定所有的城市和航班,以及出发城市 src 和目的地 dst,你的任务是找到出一条最多经过 k 站中转的路线,使得从 src 到 dst 的 价格最便宜 ,并返回该价格。 如果不存在这样的路线,则输出 -1。
示例 1:
输入:
n = 3, edges = [[0,1,100],[1,2,100],[0,2,500]]
src = 0, dst = 2, k = 1
输出:200
解释:
城市航班图如下
从城市 0 到城市 2 在 1 站中转以内的最便宜价格是 200,如图中红色所示。
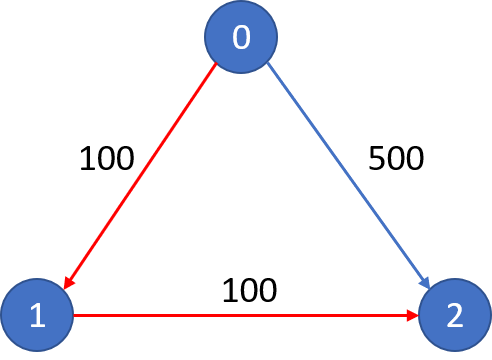
示例 2:
输入:
n = 3, edges = [[0,1,100],[1,2,100],[0,2,500]]
src = 0, dst = 2, k = 0输出:500
解释:
城市航班图同上。从城市 0 到城市 2 在 0 站中转以内的最便宜价格是 500,如图中蓝色所示。
提示:
1 <= n <= 1000 <= flights.length <= (n * (n - 1) / 2)flights[i].length == 30 <= from_i, to_i < nfrom_i != to_i1 <= price_i <= 104- 航班没有重复,且不存在自环
0 <= src, dst, k < nsrc != dst
题解(BFS+剪枝)
待更新。
完整代码:
1 | public class Solution { |

🟢 2021.08.23 (1646. 获取生成数组中的最大值)
题目
给你一个整数 n 。按下述规则生成一个长度为 n + 1 的数组 nums :
nums[0] = 0nums[1] = 1- 当
2 <= 2 * i <= n时,nums[2 * i] = nums[i] - 当
2 <= 2 * i + 1 <= n时,nums[2 * i + 1] = nums[i] + nums[i + 1]
返回生成数组 nums 中的 最大 值。
示例 1:
1 | 输入:n = 7 |
示例 2:
1 | 输入:n = 2 |
示例 3:
1 | 输入:n = 3 |
提示:
0 <= n <= 100
题解
没什么好写的,按题目要求计算 nums 数组,然后返回最大值就行了。
1 | public class Solution { |

🟠 2021.08.22 (789. 逃脱阻碍者)
题目
你在进行一个简化版的吃豆人游戏。你从 [0, 0] 点开始出发,你的目的地是 target = [xtarget, ytarget] 。地图上有一些阻碍者,以数组 ghosts 给出,第 i 个阻碍者从 ghosts[i] = [xi, yi] 出发。所有输入均为 整数坐标 。
每一回合,你和阻碍者们可以同时向东,西,南,北四个方向移动,每次可以移动到距离原位置 1 个单位 的新位置。当然,也可以选择 不动 。所有动作 同时 发生。
如果你可以在任何阻碍者抓住你 之前 到达目的地(阻碍者可以采取任意行动方式),则被视为逃脱成功。如果你和阻碍者同时到达了一个位置(包括目的地)都不算是逃脱成功。
只有在你有可能成功逃脱时,输出 true ;否则,输出 false 。
示例 1:
1 | 输入:ghosts = [[1,0],[0,3]], target = [0,1] |
示例 2:
1 | 输入:ghosts = [[1,0]], target = [2,0] |
示例 3:
1 | 输入:ghosts = [[2,0]], target = [1,0] |
示例 4:
1 | 输入:ghosts = [[5,0],[-10,-2],[0,-5],[-2,-2],[-7,1]], target = [7,7] |
示例 5:
1 | 输入:ghosts = [[-1,0],[0,1],[-1,0],[0,1],[-1,0]], target = [0,0] |
提示:
1 <= ghosts.length <= 100ghosts[i].length == 2-104 <= xi, yi <= 104- 同一位置可能有 多个阻碍者 。
target.length == 2-104 <= xtarget, ytarget <= 104
题解
在写题解之前,首先实在忍不住要吐槽,此题的歧义太大了!。。竟然还是谷歌的面试题,无语。
题目说 ghosts 是抓捕玩家的,且只要有可能成功逃脱,就应当返回 true,然而以 示例2 为例,若 player_and_ghost = [[0,0],ghost[0]] 按照 [[0,-1],[0,0]] → [[1,-1],[0,-1]] → [[2,-1],[1,-1]] → [[2,0],[2,-1]] 移动,玩家是完全能够成功逃脱的,且在这个过程中 ghost 同样在全力抓捕玩家(题目说了阻碍者可以采取任何行动方式),但该示例的输出却是 false,实在令人费解。
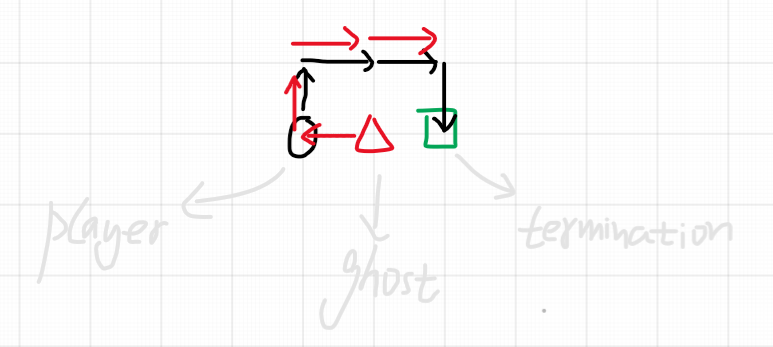
一开始以为是翻译的锅,结果看了看原题,表述同样是”有可能逃脱“:
Return
trueif it is possible to escape, otherwise returnfalse.
我猜想此题出题人是以 ghosts 和玩家谁能先到终点为出题点,然后为了考察面试者的问题转化能力,于是将谁先到终点这一表述改成了看上去相当复杂的玩家有没有可能逃脱 ghosts 追捕这一表述,然而这两者完全不等价,结果便是弄巧成拙,令人哑语,此题可谓烂出了高度,烂出了境界,烂得登峰造极!
吐槽结束。该题目的正确表述应当是:”只有在你一定能成功逃脱时,输出 true“ 而不应是 “只有在你可能成功逃脱时,输出 true“,照这样来,问题才被转换为比较 ghosts 和玩家谁能够最先跑到终点,因为只要任一 ghost 先到终点并保持不动,玩家才会完全不存在逃脱的可能性,这同时这也是本题的最优解法。
由于移动只能上下左右,且移动速度是一致的,故谁先到达终点连距离都不需算,直接比较玩家与 ghost 们各自同终点为对角线构成矩形的一半周长即可。完整代码如下:
1 | public class Solution { |

🟠 2021.08.21 (443. 压缩字符串)
题目
给你一个字符数组 chars ,请使用下述算法压缩:
从一个空字符串 s 开始。对于 chars 中的每组 连续重复字符 :
- 如果这一组长度为
1,则将字符追加到s中。 - 否则,需要向
s追加字符,后跟这一组的长度。
压缩后得到的字符串 s 不应该直接返回 ,需要转储到字符数组 chars 中。需要注意的是,如果组长度为 10 或 10 以上,则在 chars 数组中会被拆分为多个字符。
请在 修改完输入数组后 ,返回该数组的新长度。
你必须设计并实现一个只使用常量额外空间的算法来解决此问题。
示例 1:
输入:chars = [“a”,”a”,”b”,”b”,”c”,”c”,”c”]
输出:返回 6 ,输入数组的前 6 个字符应该是:[“a”,”2”,”b”,”2”,”c”,”3”]
解释:
“aa” 被 “a2” 替代。”bb” 被 “b2” 替代。”ccc” 被 “c3” 替代。
示例 2:
输入:chars = [“a”]
输出:返回 1 ,输入数组的前 1 个字符应该是:[“a”]
解释:
没有任何字符串被替代。
示例 3:
输入:chars = [“a”,”b”,”b”,”b”,”b”,”b”,”b”,”b”,”b”,”b”,”b”,”b”,”b”]
输出:返回 4 ,输入数组的前 4 个字符应该是:[“a”,”b”,”1”,”2”]。
解释:
由于字符 “a” 不重复,所以不会被压缩。”bbbbbbbbbbbb” 被 “b12” 替代。
注意每个数字在数组中都有它自己的位置。
提示:
1 <= chars.length <= 2000chars[i]可以是小写英文字母、大写英文字母、数字或符号
题解
此题不难,且容易发现并不需要额外设置 s 串再转储回 chars 中,完全可以在遍历原字符数组 chars 的过程中就地修改 chars 完成要求。
首先设置一个 hold 字符变量,用于存储重复首字符,再设置一个 contiCount 整形变量,用于存储连续重复的 hold 字符数。利用一个初值为 0 的整形 pointer 变量作为覆写 chars 的位置指针,时刻指向下一次要写入的位置,这样 pointer 的值也就同时代表了题目要求返回的数组长度。
在最开始时,hold 是空字符,直接将第一个字符设置为 hold,覆写自己,移动 pointer 并将 contiCount 设置为1,代表重复字符数为1,即字符本身。
此后,当遍历到的字符与 hold 相同时,说明出现的是重复字符,将 contiCount 自增以更新重复字符数;当遍历到的字符与 hold 不同时,说明出现了新字符,此时将之前重复字符的 contiCount 拆分写入 chars后,即可更新 hold 记录为新字符,并将新字符覆写入 chars ,contiCount 重置为1,以此类推。由于期间都是使用移动的 pointer 来指向要覆写的 chars 位,因此每次写入操作都要将 pointer 移动一位。
这里我以压缩字符数组 ['a','b','b','b','c'] 为例,画了一个压缩过程图解,辅助理解。
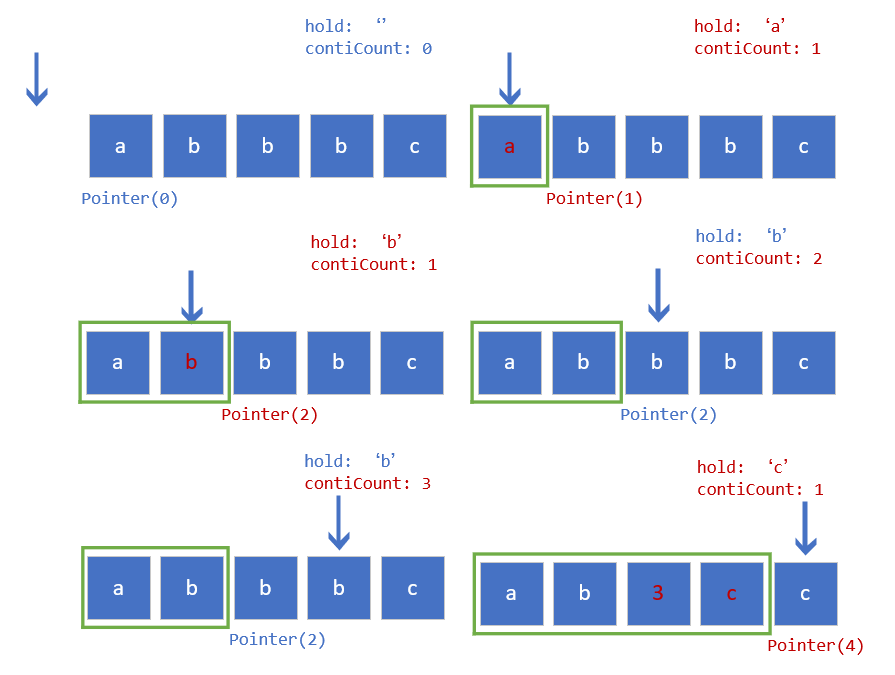
显然,该方法需要遍历一次原数组,且只使用了两个 int 和一个 char 变量,故时间复杂度为 $O(n)$,空间复杂度为 $O(1)$。
完整代码:
1 | public class Solution { |

🟢 2021.08.20 (541. 反转字符串 II)
题目
给定一个字符串 s 和一个整数 k,从字符串开头算起,每 2k 个字符反转前 k 个字符。
- 如果剩余字符少于
k个,则将剩余字符全部反转。 - 如果剩余字符小于
2k但大于或等于k个,则反转前k个字符,其余字符保持原样。
示例 1:
输入:s = “abcdefg”, k = 2
输出:“bacdfeg”
示例 2:
输入:s = “abcd”, k = 2
输出:“bacd”
提示:
1 <= s.length <= 104s仅由小写英文组成1 <= k <= 104
题解
此题不难,只需按一般情况逆置 k 位字符,然后将字符指针以 2k 长度为单位进行跳转,直接跳转到下一个逆置起点,继续逆置 k 位,以此类推即可。本题我使用 for 循环的循环变量来控制跳转,同时利用 for 循环的循环条件来判断接下来是否够 k 位,进而可以避免循环内部再做 if 判断。
对于最后可能剩下的不够 k 位的情况,单独用一个 if 来捕获,进行剩余字符的逆置。这里我画了一幅图展示完整过程,以供理解。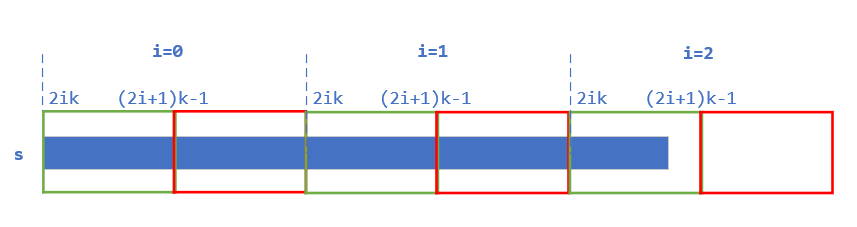
理清了思路,代码也就水到渠成了,完整代码:
1 | public class Solution { |
🟢 2021.08.19 (345. 反转字符串中的元音字母)
题目
编写一个函数,以字符串作为输入,反转该字符串中的元音字母。
示例 1:
输入:“hello”
输出:“holle”
示例 2:
输入:“leetcode”
输出:“leotcede”
提示:
- 元音字母不包含字母 “y” 。
题解
这题还是比较简单的。反转元音字母本质上也就是逆置数组,只需要设置首尾指针然后进行对调即可。只不过要逆置的元素中间插入了一些干扰项,因此需要先将首尾指针先定位到需要调换的元素位置上然后再进行调换,有点类似于快排找枢轴的过程。
但是有一点比较坑的是,题目没有特别说明可能含大写字母,因此在判断元音字母时这点需要额外注意。
完整代码:
1 | public class Solution { |

🔴 2021.08.18 (552. 学生出勤记录 II)
题目
可以用字符串表示一个学生的出勤记录,其中的每个字符用来标记当天的出勤情况(缺勤、迟到、到场)。记录中只含下面三种字符:
'A':Absent,缺勤'L':Late,迟到'P':Present,到场
如果学生能够 同时 满足下面两个条件,则可以获得出勤奖励:
- 按 总出勤 计,学生缺勤(
'A')严格 少于两天。 - 学生 不会 存在 连续 3 天或 连续 3 天以上的迟到(
'L')记录。
给你一个整数 n ,表示出勤记录的长度(次数)。请你返回记录长度为 n 时,可能获得出勤奖励的记录情况 数量 。答案可能很大,所以返回对 109 + 7 取余 的结果。
示例 1:
输入:n = 2
输出:8
解释:
有 8 种长度为 2 的记录将被视为可奖励:
“PP” , “AP”, “PA”, “LP”, “PL”, “AL”, “LA”, “LL”
只有”AA”不会被视为可奖励,因为缺勤次数为 2 次(需要少于 2 次)。
示例 2:
输入:n = 1
输出:3
示例 3:
输入:n = 10101
输出:183236316
提示:
1 <= n <= 10^5
题解(DFS+记忆化搜索)
这题自己没做出来,看了一眼别人的题解才瞬间被点通了,以后这种序列问题都应该有意识地考虑递归解法结合记忆化搜索来优化。虽然这题的难度系数是困难,但是完全没做出来实在是不应该啊,还是自己太菜了。。
首先需要能够想到基础的递归写法。要统计符合条件的序列数量,那么我们从第一位置开始选字母,然后选好后再选下一位的字母。只有这一位字母的选择满足题目条件才有资格去选下一位字母,这样只要选完了最后一位字母,就找到了一条有效序列。并且由于是每位每种有效情况的字母都遍历了,因此可以做到不重不漏。
定义 int NextDay(int day, int a, int l, int n) 是选下一位字母的递归函数,返回这个参数情况下满足题意的序列个数。因为判断条件和之前状态有关联,因此需要两个参数 a 和 l 把之前状态传进来,其中 a 是前面出现的 Absent 的次数,l 是前面连续出现的 Late 的次数。
1 | public int NextDay(int day, int a, int l, int n) |
本题的递归逻辑就是这样了,很简洁,也很直觉,很可惜自己并没有往这个方面想,菜是原罪。
当然,直接这样提交的话是会超时的,不过用记忆化搜索优化一下就好了,这个不难。当然这题也可以DP解,但暂时先止步于记忆化搜索,之后DP当专题来专门学习,然后再回过头来拿这些题目练习复习。
DFS+记忆化搜索版完整代码:
1 | public class Solution { |

🟢 2021.08.17 (551. 学生出勤记录 I)
题目
给你一个字符串 s 表示一个学生的出勤记录,其中的每个字符用来标记当天的出勤情况(缺勤、迟到、到场)。记录中只含下面三种字符:
'A':Absent,缺勤'L':Late,迟到'P':Present,到场
如果学生能够 同时 满足下面两个条件,则可以获得出勤奖励:
- 按 总出勤 计,学生缺勤(
'A')严格 少于两天。 - 学生 不会 存在 连续 3 天或 连续 3 天以上的迟到(
'L')记录。
如果学生可以获得出勤奖励,返回 true ;否则,返回 false 。
示例 1:
输入:s = “PPALLP”
输出:true
解释:学生缺勤次数少于 2 次,且不存在 3 天或以上的连续迟到记录。
示例 2:
输入:s = “PPALLL”
输出:false
解释:学生最后三天连续迟到,所以不满足出勤奖励的条件。
提示:
1 <= s.length <= 1000s[i]为'A'、'L'或'P'
题解
这题没什么好解的,直接按直觉写就击败100%用户了。
1 | public class Solution { |

🟠 2021.08.16 (526. 优美的排列)
题目
假设有从 1 到 N 的 N 个整数,如果从这 N 个数字中成功构造出一个数组,使得数组的第 i 位 (1 <= i <= N) 满足如下两个条件中的一个,我们就称这个数组为一个优美的排列。条件:
- 第 i 位的数字能被 i 整除
- i 能被第 i 位上的数字整除
现在给定一个整数 N,请问可以构造多少个优美的排列?
示例1:
输入: 2
输出: 2
解释:第 1 个优美的排列是 [1, 2]:
第 1 个位置(i=1)上的数字是1,1能被 i(i=1)整除
第 2 个位置(i=2)上的数字是2,2能被 i(i=2)整除第 2 个优美的排列是 [2, 1]:
第 1 个位置(i=1)上的数字是2,2能被 i(i=1)整除
第 2 个位置(i=2)上的数字是1,i(i=2)能被 1 整除
说明:
- N 是一个正整数,并且不会超过15。
题解(DFS)
看完题目首先想到的是暴力解法,即遍历每一位(第 i 位),在每位上再遍历 $[1,N]$ 范围内的所有数,依次选取第 i 位上能够放上的所有满足构成优美排列的数字并进行下一位数的选取,当最后一位数也选取完成后,就构造出了一个优美排列,即
1 | // index: 第 i 位 |
但是这样还有一个问题,即当某个数字 i 在某位处被选取后,是不应当在后面的位处再被选取的,因此我们需要在进入下一位递归前,为当前选取的数字做一个标记,防止被再次选中,并且在递归回溯时取消标记(因为回溯后当前位使用 i 的情况就结束了,通过for循环继续遍历使用其它数的情况)
完整代码:
1 | public class Solution { |

🟠 2021.08.15 (576. 出界的路径数)
题目
给你一个大小为 m x n 的网格和一个球。球的起始坐标为 [startRow, startColumn] 。你可以将球移到在四个方向上相邻的单元格内(可以穿过网格边界到达网格之外)。你 最多 可以移动 maxMove 次球。
给你五个整数 m、n、maxMove、startRow 以及 startColumn ,找出并返回可以将球移出边界的路径数量。因为答案可能非常大,返回对 $10^9 + 7$ 取余 后的结果。
示例 1:
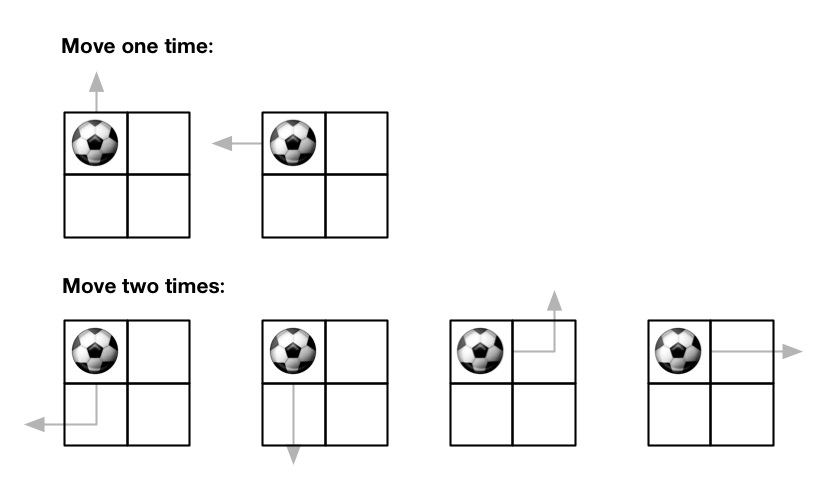
输入:m = 2, n = 2, maxMove = 2, startRow = 0, startColumn = 0
输出:6
示例 2:
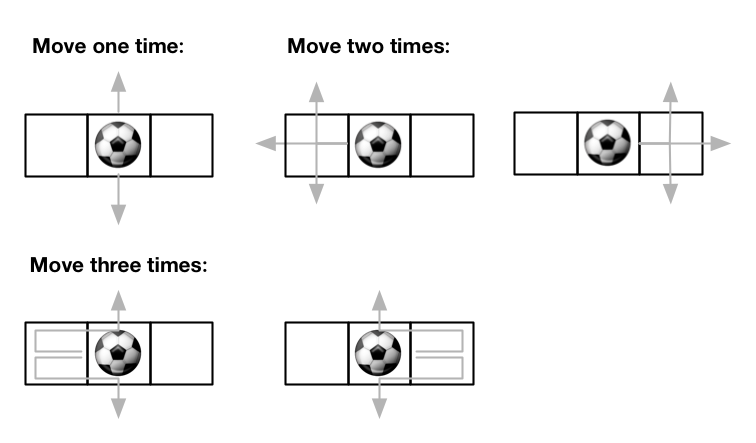
输入:m = 1, n = 3, maxMove = 3, startRow = 0, startColumn = 1
输出:12
提示:
1 <= m, n <= 500 <= maxMove <= 500 <= startRow < m0 <= startColumn < n
题解(DFS+记忆化搜索)
读完题目,很自然地可以想到通过递归来解决问题。首先不考虑各种限制。
因为第 i 行 j 列最多移动 maxMove 步的出界路径数就是当前格子处移动一步可能的出界数再加上上下左右四个格子处最多移动 maxMove - 1 步的出界路径数的和。
即,若定义 PathCount(int m, int n, int maxMove, int startRow, int startColumn) 为第 startRow 行 startRow 列在 mxn 网格中最多移动 maxMove 步的路径数 count,则
1 | int PathCount(int m, int n, int maxMove, int startRow, int startColumn){ |
如果将 count 设置为全局变量,在递归过程中更新这个量的话,那么就是
1 | int PathCount(int m, int n, int maxMove, int startRow, int startColumn){ |
那么具体在 PathCount 中,如何实际地更新 count (当前格移动一步的出界数)呢?即什么情况说明已经找到了一条出界路径?
不难想到,当 maxMove 大于 0,即球还可以移动的前提下,若当前所在行号为 0,那么就一定能够向上出界,即找到了一条出界路径,可以将 count++。同理,若当前所在列号为 0、当前所在行号为 m - 1(底边界处)、当前所在列号为 n - 1(右边界处)时也是有效的出界路径。因此 count 的实际更新可以被归结为以下四种情况
1 | if(startRow == 0) count++; |
接下来只需要考虑递归出口即可。不难想到,当前位置处于网格之外,或者不能够再移动(maxMove为0)时就到达出口了。
1 | // 出口条件 |
至此,可以得到如下直觉解法
1 | public class Solution { |
这样确实可以解决问题。但是,当输入参数过大导致递归深度过深时,运行时间会爆炸式增长。稍加分析可以发现,在第0层递归时的第一个 PathCount 调用栈中遍历过的格子,可能在后续递归中被大量重复访问,不仅重复访问,而且还会重复开启递归栈,造成时间爆炸。
因此我们可以设置一个变量(int[,,] mem),记录某格处最大走 maxMove 步对应的已经计算过的路径数量,在访问该格时,首先检查变量中该位置最大走 maxMove 步是否有值了,如果有就直接可以直接返回,省去所有重复的递归栈,以此优化原算法,此思想即为记忆化搜索。
最终完整代码:
1 | public class Solution { |

⚪ 2021.08.14 (1583. 统计不开心的朋友)
🟠 未做
⚪ 2021.08.13 (233. 数字 1 的个数)
🔴 不会
⚪ 2021.08.12 (516. 最长回文子序列)
题目
给你一个字符串 s ,找出其中最长的回文子序列,并返回该序列的长度。
子序列定义为:不改变剩余字符顺序的情况下,删除某些字符或者不删除任何字符形成的一个序列。
示例 1:
输入:s = “bbbab”
输出:4
解释:一个可能的最长回文子序列为 “bbbb” 。
示例 2:
输入:s = “cbbd”
输出:2
解释:一个可能的最长回文子序列为 “bb” 。
提示:
1 <= s.length <= 1000s仅由小写英文字母组成
题解
🟠 待更新
完整代码:
1 | public class Solution { |
⚪ 2021.08.11 (446. 等差数列划分 II)
🔴 不会
🟠 2021.08.10 (413. 等差数列划分)
题目
如果一个数列 至少有三个元素 ,并且任意两个相邻元素之差相同,则称该数列为等差数列。
- 例如,
[1,3,5,7,9]、[7,7,7,7]和[3,-1,-5,-9]都是等差数列。
给你一个整数数组 nums ,返回数组 nums 中所有为等差数组的 子数组 个数。
子数组 是数组中的一个连续序列。
示例 1:
输入:nums = [1,2,3,4]
输出:3
解释:nums 中有三个子等差数组:[1, 2, 3]、[2, 3, 4] 和 [1,2,3,4] 自身。
示例 2:
输入:nums = [1]
输出:0
提示:
1 <= nums.length <= 5000-1000 <= nums[i] <= 1000
题解
这题按直觉解就很容易解,依次将第 i 个元素作为子数组的首元素,然后利用首元素和下一个元素计算该子数列的公差,然后开始向后检查,只要每一个元素和前一个元素之差等于公差,那么都构成一个等差子数列,直到与前一位之差不等于公差,第 i 个元素作为首元素就不存在更多等差子数列了,将 i++ 进行后续判断。
如1234578,先将首位设置为第一个元素1,然后利用(12)计算出公差为1,往后(123)中(23)之差为1,就是一个子数列,往后(1234)中(34)之差也为1也是子数列,(12345)中(45)也是,但(123457)中(57)就不是了,那么再往后也不可能再是等差数列了,于是将首位设置为第二个元素同理搜索。
1 | public class Solution { |

🟠 2021.08.09 (313. 超级丑数)
题目
超级丑数 是一个正整数,并满足其所有质因数都出现在质数数组 primes 中。
给你一个整数 n 和一个整数数组 primes ,返回第 n 个 超级丑数 。
题目数据保证第 n 个 超级丑数 在 32-bit 带符号整数范围内。
示例 1:
输入:n = 12, primes = [2,7,13,19]
输出:32
解释:给定长度为 4 的质数数组 primes = [2,7,13,19],前 12 个超级丑数序列为:[1,2,4,7,8,13,14,16,19,26,28,32] 。
示例 2:
输入:n = 1, primes = [2,3,5]
输出:1
解释:1 不含质因数,因此它的所有质因数都在质数数组 primes = [2,3,5] 中。
提示:
1 <= n <= 1061 <= primes.length <= 1002 <= primes[i] <= 1000- 题目数据 保证
primes[i]是一个质数 primes中的所有值都 互不相同 ,且按 递增顺序 排列
题解
由于超级丑数是由质因数相乘得到的,因此给定一组质因数后,其对应的超级丑数有无数个,所以肯定是无法通过先计算出所有超级丑数,然后取第 n 个返回的思路了。故应该思考如何从小到大按顺序依次生成超级丑数。
其中一个关键点是,由于超级丑数是由质因数相乘得到的,那么就意味着任一超级丑数一定能被分解成一个质因数和一个更小的超级丑数,也即超级丑数是由更小的超级丑数同质因数生成的。那么反过来,我们借此就可以由最小的超级丑数1,遍历质因数同1相乘,来找到(生成)最小的下一个超级丑数。

现在就有了两个超级丑数,并且它们是最小的两个,那么第三个超级丑数就一定是由这两个小的超级丑数同所有质因数相乘得到的结果中最小的那个。不过需要注意的是,质因数并不需要和所有找到的超级丑数相乘再比较,因为我们要找的是最小的那个,只需要和允许相乘的最小的那一个超级丑数相乘就行了,比如质因数4和第 1 个超级丑数相乘了,那么这个质因数就没有必要和第 2 个以及后面的超级丑数相乘了,因为往后一定是乘出来更大的数。
那么如何知道某个质因数应当和第几个超级丑数相乘呢?其实只需要设置一个(质因数->超级丑数)指针,最开始所有质因数都是和最小的超级丑数相乘,当某个质因数 x 被选出来同1相乘的结果最小时,生成了第二个超级丑数,此后 x 就不可能再和 1 相乘了,因此 x 对应的指针就可以向后移动到第二个超级丑数的位置,后面只需要和第二个超级丑数乘就是 x 能生成的最小的超级丑数。
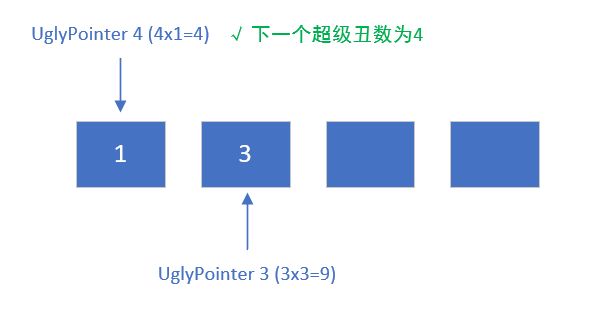
依次类推,生成到第 n 个超级丑数,就得到了本题的答案。
此外,如果有其它质因数和其指针对应的超级丑数相乘的结果和生成的下一个超级丑数相同,那么这个质因数的指针也应该后移一位,因为相同的超级丑数没有意义,应当指向下一位能生成大于当前超级丑数序列中最大超级丑数的最小超级丑数。
完整代码:
1 | public class Solution { |
